

Durable access to book historical data
A project to FAIRify a rich, existing dataset on the historical Leiden book industry shows how the data can be made more durable and accessible leading to more reproducible, more collaborative and more open scholarship.
Researchers who share their research data typically do this because they aim to enable the reuse of their scholarly output. The findings developed in one particular study may form a source of inspiration for other researchers, and, if the underlying data are archived, these colleagues can build upon these data to produce new knowledge.
While it is vital to ensure that data are made accessible via certified repositories, there are a number of additional conditions which can help to promote the actual reuse. The methods that have been used to create the data need to be documented well, and the data also need to be structured according to well-documented data formats. The reuse is generally easier, moreover, when the data have been described using broadly accepted vocabularies.
If the data sets which have been produced during a research project are unstructured or undocumented, it is advisable to reorganise or to transform the data set and the associated metadata before they are deposited into an archive.
Interesting data on the historical Leiden book industry
To develop a better understanding of the factors that contribute to the reusability of research data, the Leiden University Centre for Digital Scholarship has participated in a research project which aimed to convert an existing semi-structured born digital archive into a more organised data set. The project concentrated, more specifically, on the scholarly archive of Professor Paul Hoftijzer, a book historian affiliated with the Leiden University Centre for Arts in Society.
Prof. Hoftijzer’s archive resulted from a very extensive book historical research programme, conducted over the course of several decades, in a range of archival institutions in Leiden and in other cities. It contains detailed descriptions of people, organisations and events relevant to the Leiden book industry in Leiden in the early modern period.

Image: A bookshelf in the Bibliotheca Thysiana, one of the collections studied in the project.
It is a very rich archive, which can be extremely valuable to future generations of book historians interested in the Leiden book trade. It is of importance, for this reason, to make sure that these data remain accessible and that researchers can continue to make use of these born-digital data.
Solving problems that made re-use difficult
Initially, however, the data set had a number of properties which could complicate academic reuse. The data were produced using a descriptive standard which has evolved organically over the course of several years. There is a clear logic underlying all of these data, but without an explicit explanation of the abbreviations, the cross-references and notational conventions concocted by the creator of the archive, it can obviously be difficult for colleagues to make a productive use of this rich source of information.
The data were captured, furthermore, as free text in the text editor Microsoft Word. This format does not immediately allow for systematic searches. In the original files, it was difficult to produce counts of the total number of people described in this data set, for example, or of the number of people within specific professions within the book trade.
During an initial phase of the project, the nature and the structure of the data have been examined thoroughly. The results of these analyses were captured in a number of data models. Once the structure of the data sets had been clarified, conversion software was developed in the Python programming language. The code that was developed aimed to recognise particular data values on the basis of regular expressions.
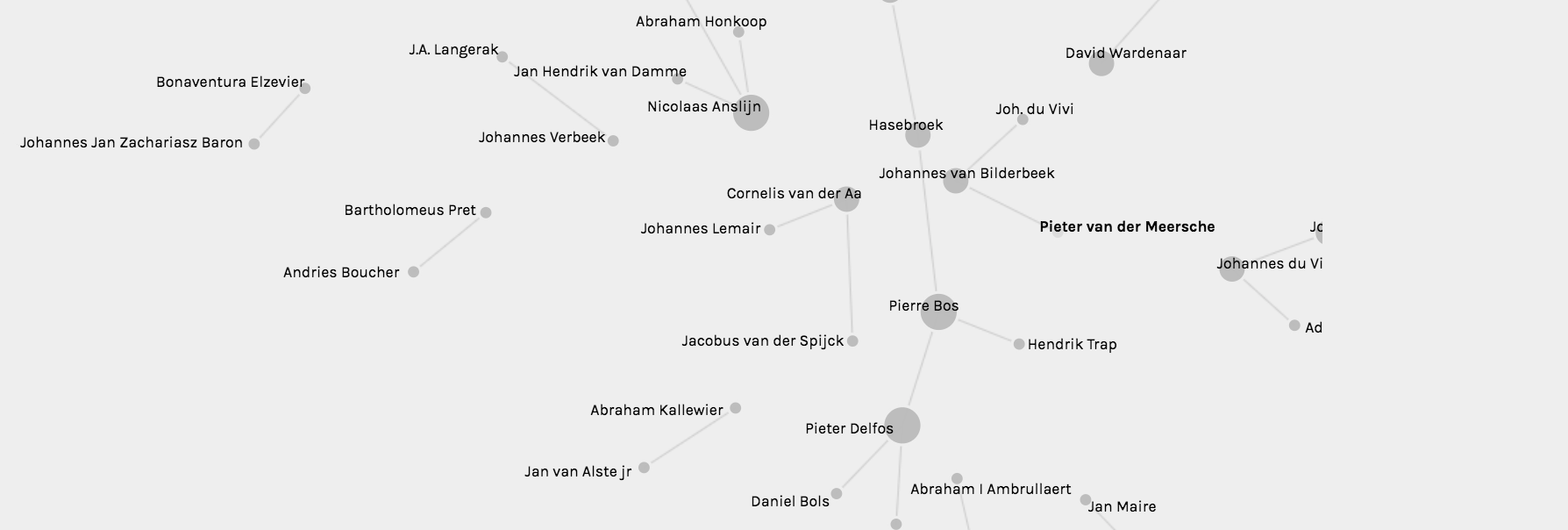
Image: Analysis of the social network of Seventeenth Century printers based in Leiden.
How interoperability meant that data connections could be made
In the original semi-structured data set describing people, places and organisations in the Leiden book trade, Prof. Hoftijzer had fortunately made use of explicit labels to indicate properties such as names, functions, years of activity and addresses.
The labels used to describe the data values have been connected to terms in existing vocabularies whenever possible, and many of the people, places and organisations in the data set have also been connected to entries in external data sets, including WikiData, GeoNames and the Short Title Catalogue of the Netherlands.
Though activities such as these, the semi-structured research annotations could be converted into a searchable and interoperable relational database.
New research on old data is now possible
The structured data set that has been created in this project has already been used in a university course at the BA-level, taught during the first half of 2019. During this course, named "Boekgeschiedenis in de praktijk”, students were stimulated to explore the research potential of the digital archive that was made available.
After a number of introductory lectures, clarifying the historical context of the born-digital archive, the students had defined their own research projects. Among other research topics, the data have been used to study the history of the guild of booksellers in Leiden, the network of family relations, the influx of foreigners in the Leiden book trade and the occurrences of banned books on the catalogues of book actions organised in Leiden.
As a result of these research projects, the database could be refined and improved in a number of important ways.
This project, which was formally completed in August 2019, has produced valuable insights into the concrete steps that need to be taken to promote the scholarly reuse of research data. Some of the insights have also been documented in a report (published in Zenodo: Top 10 FAIR Data and Software Things) which was written in close collaboration with the Library Carpentry Foundation and the Australian Research Data Commons.
Projects and activities such as these, in which ill-documented or semi-organised archives are reorganised so as to become more compliant with the FAIR data management principles, can be very helpful for researchers. The enhancement and the FAIRification of existing data sets can clearly contribute to a more durable and a more productive form of access to these data, and activities and services in this field ultimately help scholarship in general to become more reproducible, more collaborative and more open.


