Using Twitter data to study the responses to the attacks on Charlie Hebdo
During the past few years, data extracted from the social media platform Twitter have increasingly been on the radar of researchers interested in contemporary developments or in responses to recent events.
With more than 350 million active users, Twitter has evolved into one of the world’s leading hubs for the dissemination and the consumption of information about life and society in the 21st century. The platform probably owes its popularity in academic research in large part to the fact that its data can be accessed quite efficiently via a range of Application Programming Interfaces (APIs). While the free API accounts still have a number of limitations, the academic API account offers its users access to virtually any tweet posted since the inception of the platform in 2006, provided, obviously, that it is public and that it has not been deleted. Once the academic account is granted, users can download up to 10 million tweets per month, a number which will probably be sufficient for the majority of applications. Next to the tweets themselves, researchers can also extract relevant metadata fields, such as the time and the date on which the tweet was posted, the language, the name of the Twitter user, and the number of likes and retweets. In recent years, the task of working with tweets has become much easier because of the launch of tools and frameworks such as rTweet for R and Twthon and Tweepy for Python.
Twitter data become research data
Twitter data also form one of main primary sources for the research conducted by Zeynep Aydin, a PhD researcher affiliated with the EU-funded project Mediating Islam in the Digital Age. Aydin’s research aims to study the impact of the various Jihadist terror attacks that have been perpetrated in Europe since 2015, and to understand how these attacks have affected public and private perceptions of Islam and of Islamism. Aydin has been collaborating with the Centre for Digital Scholarship since 2021, and, from 28 March to 8 April 2022, she participated in a research secondment at the CDS in Leiden to work intensively on a specific set of tasks within her overarching PhD project, entitled “The Ticking Time Bomb: the Role of Islamophobia in Hashtag Activism after Terror Attacks in Europe”. The secondment focused, more specifically, on the terrorist attacks that took place in the offices of the French satirical newspaper Charlie Hebdo and on other locations in Paris between 7th and 9th January. As was the case for many recent topical events, millions of people have shared their reactions to these attacks immediately via Twitter.
In the research project, a decision was taken to concentrate on the tweets that were posted in between 7th and 11th January 2015 and that contained the hashtags #JeSuisCharlie or #CharlieHebdo. These tweets, and the metadata associated with these tweets, were all downloaded via the Twitter API for academic research. It is clear that the Charlie Hebdo attacks generated vast amounts of traffic on Twitter. During the five days following the first attack, the hashtags #JeSuisCharlie and #CharlieHebdo were used in 6.650.184 tweets in total, amounting to 55.418 tweets per hour. About 2.9 million of these tweets were in French, and ca. 2.5 million tweets were in English. Other common languages include Spanish (587.191 tweets), Italian (207.722 tweets), and German (99.974 tweets). The dataset contains 1.656.435 original tweets. About 75% of the tweets were actually retweets. The tweet that was retweeted most frequently during this period was a tweet by the Australian cartoonist David Pope. This tweet contained a cartoon which he drew only 5 hours after the attack on the Charlie Hebdo office. In the five days following its publication, this post was retweeted 58279 times. Interestingly, the 10 most frequently retweeted tweets were all from authors, cartoonists, comedians and youtubers, including Cyril Hanouna and J.K. Rowling. Tweets posted by official news agents, such as @BBCNews, received considerably fewer retweets.
Classification and analysis of tweets
One of the central objectives of Zeynep Aydin’s project is to analyse the views and the opinions that are expressed in these tweets, and to examine the ways in which these different camps interacted. Additionally, a key objective of this research is to identify retweet behavior and to identify the characteristics of the posts that went viral shortly after the attack had been perpetrated. Based on an initial close reading of the ca. 500.000 original tweets in English, seven main camps or clusters were identified.
- A first cluster was formed by Twitter users who condemned the attacks, and who expressed a strong anti-Muslim sentiments.
- A second camp consisted of the users who felt the need to defend the freedom of expression of the cartoonists who worked for Charlie Hebdo, in an aggressive manner.
- Similarly, a third camp sought to do the same, but in a more peaceful and acquiescent manner.
- By contrast, there were also many Twitter users who defended the attacks, and who vehemently condemned satirical depictions of the prophet Muhammed.
- A fifth camp expressed a call for solidarity, and aimed to create a level of mutual understanding.
- The sixth camp consisted of Twitter users who deplored the amount of attention devoted to the attacks on Charlie Hebdo, and who noted that there were many disasters and attacks taking place simultaneously in Nigeria, Palestine, and Pakistan.
- A seventh group of users simply reported on the events as these took place, without taking a firm political stance.
To investigate the prominence and the relative importance of these different camps, the original English tweet that were posted in between 7th and 11th January were initially classified, somewhat crudely, using a newly developed lexicon containing words that were assumed to be distinctive of these various types of responses. To enhance the performance of the classification, specific slang spellings such as ‘be4’ (for ‘before’) and ‘urs’ (for ‘yours’) were all regularised. The initial results of this classification were edited manually. A set of 200 representative tweets was selected for each of the seven categories, and these selected tweets formed the training data for a Deep Learning algorithm based on a convolutional neural network. Using this approach, accurate classifications were assigned to all the 50.000 original English tweets in the data set.
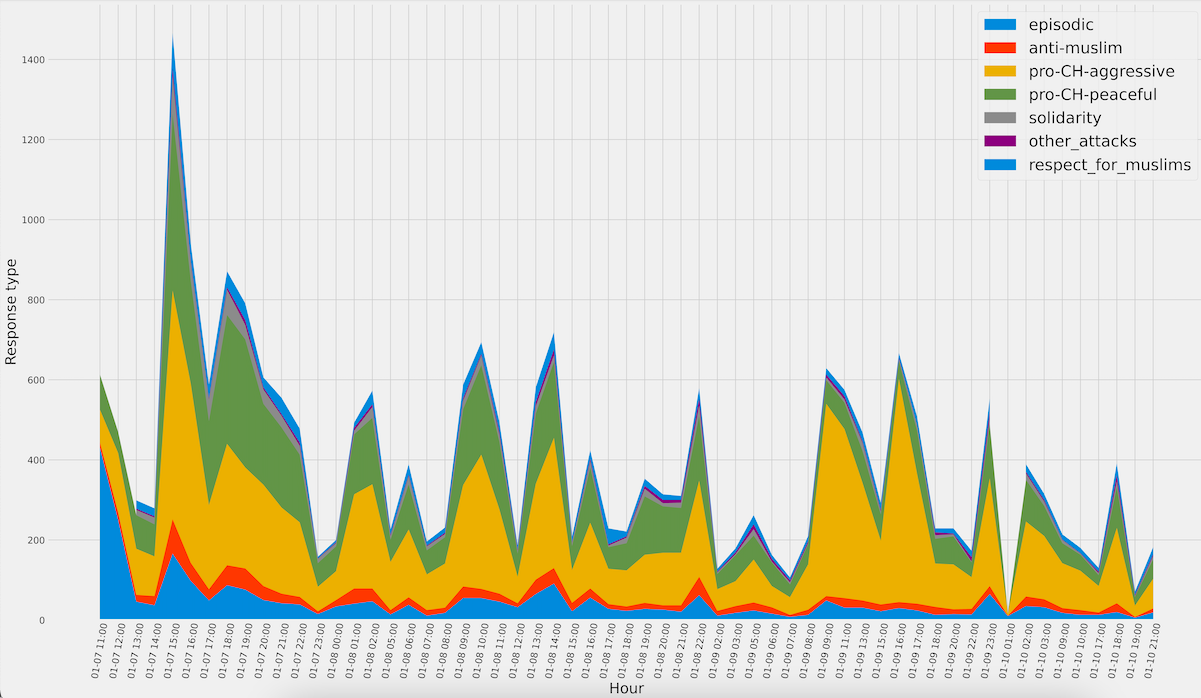
Analysis of tweets according to the 7 clusters
These classifications in turn formed the basis of a visualization which clarifies the prominence of each of these seven camps over time. The visualization shows, among other things, that the camp which defended the perspective of the Charlie Hebdo cartoonists aggressively was the most extensive during the first five days. The group expressing anti-Muslim sentiments certainly did not dominate the debate (numerically at least), but it is clear, nonetheless, that this view continued to be present throughout the first five days. The ‘episodic camp’, which consisted of those tweets which mainly reported on the events in an objective manner, was primarily dominant on the first few days. We can conjecture that Twitter users initially aimed to establish the facts, and that they started to express their position only afterwards.
While these two objectives for the research were planned prior to and executed during the secondment, working with the subject matter in collaboration with the researcher and the experts at the CDS also enabled a more detailed downloading and analysis of the Twitter data. In this vein, it was also possible to download all images that were tweeted in the aftermath of the January attacks and to organize them according to their retweet count and to analyze the most viral tweets based on the symbols detected in them.
If you are interested in working with Twitter data in a similar matter, don’t hesitate the contact the CDS to discuss your research ideas.