Dataset publication by Leiden University researchers: research on the impact of FAIR data
Núria Raga Raga joined the Centre for Digital Scholarship for a 3 month internship to determine which repositories Leiden researchers use to archive their data and to what extent these repositories enable compliance with the Leiden University Data Management Regulations.
We conducted this study to assess the storage and publication of datasets by Leiden researchers in data repositories. The results allow us to know more about characteristics of data repositories, compliance of researchers with the Leiden University Data Management Regulations, impact of datasets and practices related to FAIR data.
The main purpose of the study was to research which repositories Leiden researchers were using to archive their data and to determine to what extent these repositories enable compliance with the regulations. The reports with the results and the conclusions of this study are made from this point of view, based on the behaviour of the researchers in relation to the requirements of the Leiden University Data Management Regulations.
Data Management Regulations, protocols and guidelines
Leiden University elaborated regulations, protocols and policies regarding data management in the last years on two levels. The main document to take into account is the Data Management Regulations, first published in 2016 and reviewed in 2021. It regards the management, storage and provision of research data and intends to provide a framework for a University-wide research data management policy. Each faculty has to determine through a Data Protocol the way the regulations are fleshed out within the faculty and the specific institutes.
The institutes of Leiden University that have already created protocols or guidelines about Data Management for their researchers are:
- Faculty of Humanities
- Institute for History: “Guidelines for Data Management” (2019)
- Centre for Linguistics: “Digital Data Storage Protocol” (2018)
- Faculty of Social and Behavioural Sciences
- Institute of Education and Child Studies: “Open Science policy and guidelines” (2021)
- Institute of Psychology: “Open Science policy and guidelines” (2022)
At this moment, all the faculties of the university are working in the development of their own Data Protocols in a faculty/institute level. The writing of the protocols is a really important process to be made, and now it is being a work in progress in all the faculties. The results of our study can be helpful for the Data Protocols working groups because they can take this knowledge of the local data publication into account in the writing of their protocols, in order to suit the wishes and needs of their researchers. In that sense, we have to consider the protocols as a guide to help researchers rather than stipulating other requirements for them.
If we want to know what the Data Management Regulations say about data archiving we have to look into this article:
“Article 11: Digital research data are sustainably stored in an archive/repository, preferably a certified repository […]. The faculty/institute data protocol includes a list of preferred archives/repositories.“
The Centre for Digital Scholarship, as a support team in charge of data management in Leiden University, also makes some recommendations on data archiving and publishing in its RDM checklist:
“To ensure that data can be reused responsibly and productively, it is best to store these data in a trusted data repository. The option to archive data as supplementary materials, attached to a publication, ought to be avoided whenever possible. Data repositories have taken various measures to make sure that data can remain findable and accessible. The data which are stored in data repositories can in most cases be cited though a persistent identifier (such as the DOI). Such archives consequently enhance your visibility as a researcher.”
The questions can be: what is a trusted data repository? And what does it mean that a repository is certified? According to the Definitions List for Data Management Regulations:
“A trusted digital repository is a digital archive whose mission is to store, manage and provide reliable, long-term access to digital resources and it has been certified by an official organisation. A well-known certification for data repositories is Core Trust Seal”.
Repositories that follow certain requirements and standards can be certified. The CoreTrustSeal certification is given to repositories that meet 16 requirements that are intended to reflect the characteristics of trustworthy repositories. These requirements are related to organisational infrastructure, digital object management, information technology and security. This certification makes the data repository reliable for archiving datasets.
Two resources that can help when choosing a data repository to archive a dataset are:
- Re3data: Registry of Research Data Repositories. It gives detailed information about data repositories.
- Generalist Repository Comparison Chart: Shows a comparison of multidisciplinary/generalist repositories and their main characteristics.
Identifying datasets
In order to gather all the datasets published by Leiden University researchers, we started with the Data Monitor tool, from Elsevier. This tool allowed us to track datasets from our institution in different data repositories. This was only the starting point of the study, because after collection every dataset retrieved had to be checked manually so the results could be truly reliable.
The hardest part was to identify the authors of datasets and relate them to a specific institute/centre of the university, so the results could be more accurate for the faculties. We also had to be very clear about our definition of a “dataset”: for instance, we didn’t take into account supplementary materials for publications or records with a lack of metadata, as images or figures. We also wanted to be able to link the datasets retrieved with research articles that could be related to them.
Reports
After gathering all the information about the datasets published by Leiden researchers, several reports have been made, in order to facilitate a discipline specific overview. There is one general report, where we can see all the information analysed at university level. Then, there is also a report for each faculty of the university, where results can be more interesting because of their particularities and disciplinary framework. The reports can be consulted through these links (see footnote 3):
- General report
- Faculty reports:
- Archaeology
- Humanities
- Governance and Global Affairs
- Law
- Science
- Social and Behavioural Sciences
- Naturalis Biodiversity Center (Centre not related to a specific faculty, see footnote (1))
The best way to look into the results is interacting with the slides and figures of the reports, as they have been created for this purpose. In some slides there are filter options to be able to respond to concrete needs [editor note: this functionality is no longer available, see footnote 3].
In each report we can find this information:
- Regulations and protocols that affect the publication of datasets
- Repositories used by Leiden researchers
- Certification of the repositories
- Type of repositories
- Repositories overview
- Resources to know more
- Certification of the repositories
- Metrics of the datasets
- Year of publication of datasets
- Datasets related to articles
- Authorship of the datasets
To better understand the results of this study it is recommended to look into the reports made for each faculty, as we can also see information related to the specific institutes of the faculties.
Results
We could identify that Leiden University researchers have published 3.265 datasets (registered until October 2022). In the graphic below we can see that the majority of datasets have been published by researchers of the Science Faculty (76,4% of the datasets). It is something that does not surprise us as this faculty is the host of the largest number of data intensive research projects.
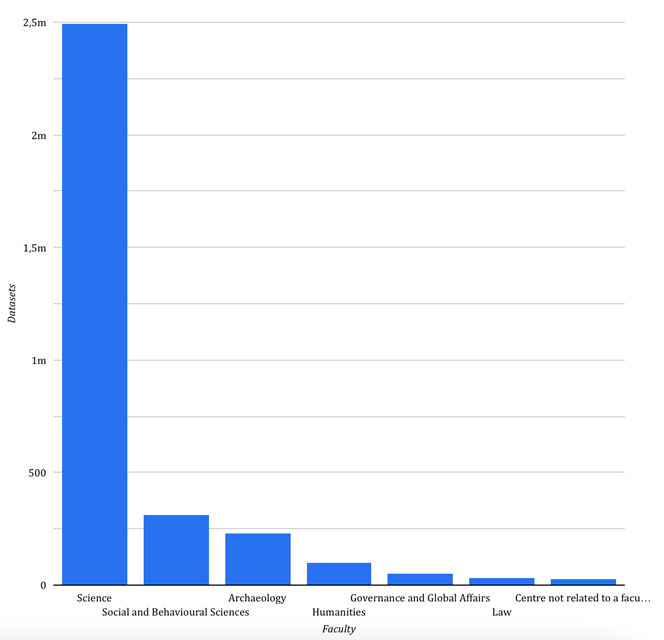
To be able to understand the results of the study is necessary to know a little bit more about the data repositories. In our study we distinguish three types of repositories:
- Institutional: it collects datasets by authors of a particular institution. In our case, DataverseNL serves as the institutional repository for two faculties at Leiden University. As an institution, we can ask for certification of the repository as the Long Term Preservation of the data is already guaranteed by DANS Data Vault.
- Disciplinary: it is related to a certain subject or area of study, so it is a domain-specific repository. Some examples of disciplinary repositories are: Strasbourg Astronomical Data Center, RCSB Protein Data Bank, DANS Data Station Archaeology...
- Generalist/Multidisciplinary: when researchers don’t have an institutional repository or don't find a useful disciplinary repository for their data, they can publish the dataset in a generalist repository, as it accepts data regardless of content, format, data type or disciplinary focus. Only the generalist repositories that serve a specific designated community can have a certification, as is the case of the EASY repository from DANS. The rest of them can’t have this certification (Zenodo, DRYAD, Harvard Dataverse...).
Taking this into account, we see that the choice of the researcher when looking for a data repository can affect the compliance of the requirements of the university, as the compliance is related to the certification of repositories. This graphic, where we can see the certification of repositories used by researchers in the different faculties, is the one that can give us an idea of the compliance:
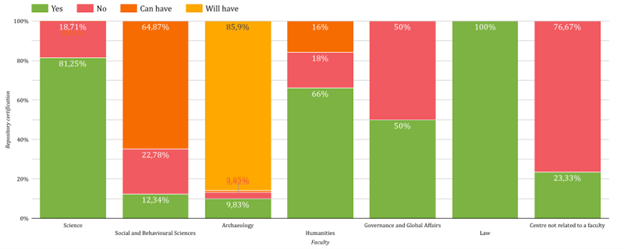
Law is the faculty where researchers are more compliant with the requirements. All the datasets from Law are published in EASY, a certified repository from DANS.
In the Science faculty, researchers tend to publish their datasets in certified disciplinary repositories, especially the researchers from the Leiden Observatory and the Institute of Chemistry. As said before, this is the faculty with more published datasets, so its compliance is really important for the general results.
Most of researchers from the Archaeology faculty have been depositing their data in EASY for many years. This was a good practice and they were really compliant with the regulations. Recently DANS has created the Data Station of Archaeology, a repository to deposit data within this field. They have migrated the datasets from EASY to the Data Station, that is not certified yet, but is expected to be certified in 2023 (see footnote (2)). That’s why in the graphic we see that the 85,9% of the datasets are published in a repository that “will have” a certification. From the point of view of the researchers publication, we can say that the 95,73% of datasets have been deposited following the regulations.
If we look into the Social and Behavioural Sciences faculty, we see that the 64,87% of the researchers publish their data in a repository that “can have” a certification, in that case this repository is the DataverseNL. Two institutes of this faculty have an “Open Science policy and guidelines” where it is said that researchers must archive a publication package in DataverseNL (Institute of Education and Child Studies and Institute of Psychology). This practice can be seen in the results of the study. The other institutes of this faculty should consider to look into certified repositories in their field or to join the other institutes in the institutional repository to improve the compliance.
Something similar happens in the Humanities faculty, where researchers of the Centre for Linguistics have the “Digital Data Storage Protocol” that says that they have to publish their data in the DataverseNL repository. The “Guidelines for Data Management” of the Institute for History say that research data must be stored in a Trusted Digital Repository, and we can see that its researchers are really compliant to this requirement.
In the Governance and Global Affairs faculty we see that some researchers prefer to use generalist repositories and that’s why there are many datasets published in not-certified repositories. The same happens with the researchers from Naturalis Biodiversity Center (it’s a centre not related to a specific faculty) where the main repositories used are generalists and not-certified.
For the rest of the results, we recommend looking into the reports for the specific details of each faculty, as they provide a useful overview of the particularities related to the various disciplines and types of research data.
Conclusions
After completing this study, we identified some issues related to the FAIRness of research data, its impact and the importance of protocols.
- One important part of this study has been the exchange of opinions and information with the Data Stewards, Data Managers and other members of staff involved in the research support. In general, we have seen that the compliance of researchers with the university requirements is good, considering that the development of a Data Management Protocol specific for their institutes is still work in progress. We think that it is really important that researchers can have these protocols as a guide in all the process of their research.
- We see that there are some practices that could be improved:
- Researchers store often their data because they “have to”, but they don’t share it or cite it. In these cases, the datasets are difficult to find and a barrier to reusability is also created.
- It is important to link the datasets to the research publications so everyone interested in the research can easily find the dataset.
- It is also important that researchers can be easily identified through a persistent identifier such as ORCID, so all the research is always linked to a specific researcher. Sometimes researchers create an ORCID account but they don’t put any information in it, so the identification and the affiliation to institutions are still not possible.
With this study we also wanted to know more about the impact of publishing datasets. We have seen that this is not so easy to prove. Only some of the repositories show us some metrics related to datasets (usually the generalist repositories). We can see how many views or downloads have the datasets but it’s not easy to relate this to the impact of the research or the researchers. To be able to know more about the impact, we should have information about publications with no datasets published so we could compare the metrics. That is something that could be studied in future research and that would be really interesting to know. But, for now, there are many things that can be improved with good practices to make research data more findable, reusable and to increase its visibility.
Footnotes
(1) Datasets from The Naturalis Biodiversity Center have been included in the study, although it is an external organisation. Researchers of the centre don’t need to comply with the regulations but some of them are staff members from the Institute of Biology (Science faculty).
(2) This article was amended on 2 February 2023. The DANS Data Station Archaeology is expected to be certified with a CoreTrustSeal in 2023. Until that time, the datasets submitted to the DANS Data Station Archaeology are also kept in the existing CTS certified environment of DANS.
(3) Editor note. This blog was amended on 22 July 2025: the original Lookerstudio/Google Datastudio links to the reports were replaced with links to PDFs, in the interest of long-term accessibility and sustainability (the images were no longer displayed in Lookerstudio and people without google account could not access the reports). Unfortunately this means the interactive functionality is no longer available. Some of the files had to be reduced in size, for the originals, please contact cds@library.leidenuniv.nl.