

Data sharing and the GDPR
Working with personal data in compliance with EU privacy legislation may already be challenging by itself; when collaborating in consortium projects with partners from outside the University, it requires dedicated knowledge and attention.
On May 17th, 2021, Leiden University Libraries' Centre for Digital Scholarship organized the second meeting of our new “Connect and...” series, that aims to bring together people working with data from various disciplines to exchange experience and share their best practices.
22 members and guests of the Leiden University Data Management Network came together in an online informative session: ‘Connect and Learn: Making data sharing possible in the context of the GDPR’.
We were happy to have two speakers, Mark Dechesne and Dorien Huijser, who elaborated on the datasets that they collected and shared, on the issues that they encountered, and the solutions that they found. After their presentations on the practical side of data sharing, the University’s Data Protection Officer, Ricardo Catalan, shared his views on the implications of privacy legislation with regards to data sharing in research projects.
Our take-away message from the session is to stress the importance for collaborative projects to have clear guidelines on how to handle and share data containing personal information and to make these guidelines known to all members in the project, be it in a handbook such as the DARE project produced, or in a dedicated 'lab-wiki' that was used in Dorien’s project.
Mark Dechesne, Associate Professor at the Faculty of Governance and Global Affairs provided us with a very interesting project document including a workflow for the processing of sensitive data in the H2020 DARE (Dialogue about Radicalisation and Equality) project. This H2020 project involves 17 academic and non-academic partners in 13 countries and deals with highly sensitive data on radicalization from interviews and observations.
Mark highlighted a positive side to research data management as a means to improve the efficacy of research and to facilitate reuse of data. By synthesizing research findings, combining data, and discussing shared findings with fellow academics, new knowledge can be created.
The approach taken by the DARE consortium is to create a database that allows for systemic processing of digital and digitized files. The data will link to observational materials without revealing the identity of participants. Pseudonymized files are shared and processed in NVIVO. An additional advantage is that a small group of participants need not be overasked.
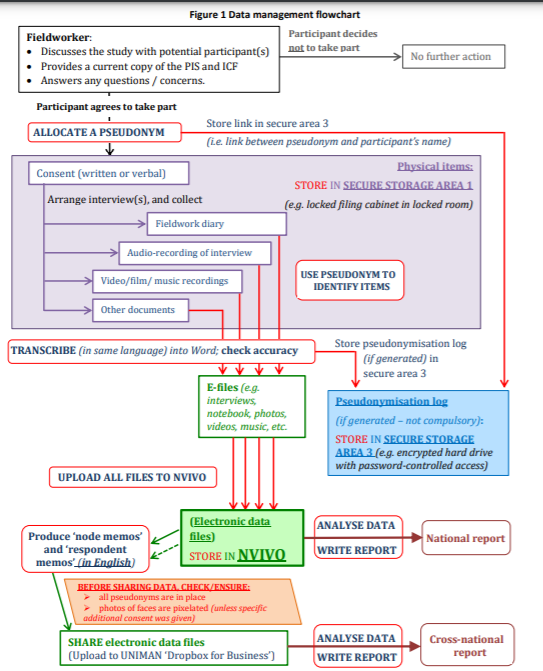
The data management flowchart in the DARE project document.
Dorien Huijser works as datamanager at the Brain and Development Research Center of the Institute of Psychology. In the mids of the pandemic, April 2020, part of the lab she works for moved to Erasmus University into a new setting. This move involved the transfer of sensitive developmental neuroscience data, but also left part of the research to be conducted in Leiden.
Dorien explained the steps they took to make the two groups work together and safely share research data that were not only BIG in size but could also include identifiable information. Data were encrypted and moved from the Leiden Network drive to ResearchDrive, a facility hosted by SURF for Erasmus
After discussion with privacy officers and the DPO, an agreement could be set up that made both groups data controller.
Ricardo Catalan, our University Data Protection Officer, summarized the challenges that Mark and Dorien encountered in his resumé of the session. Full GDPR compliance in a consortium setting is difficult to manage due to three factors:
- Transparency
As research goes on and new knowledge is acquired, there will always be changes of the initial plan, asking for questions or reuse in a manner not previously envisaged. It is nearly impossible to inform all stakeholders of changes made in the course of a project. - Data transfer
Within a consortium setting data transfer is complicated, especially when the data cross EU boundaries and will then be subject to different rules and legislation. - Control
Full control over the data is impossible to attain in a consortium setting when working on equal footing with independent partners, such as other universities.
In Ricardo’s view, the worst thing a DPO can do is to say “This is not allowed!”. What we do need is:
- More support for researchers working with personal data.
It is hard for researchers to be aware of all things you need to know outside your own field of expertise. - Additional legislation directed at the procession of personal data as part of scientific research.
During the first meeting of the ‘Connect and…’ series, representatives from three cutting edge projects discussed the success of a three-point FAIRification framework, and the opportunities for new activities at Leiden.
The next meeting of the ‘Connect and…’ series is scheduled for 15th June: Connect and Imagine: Can research software be managed?
We look forward to see you there.


