Love Data Week: And where is *your* data?
It's (almost) Love Data Week! The theme this year is 'Where 's the data?'. In this blog Femmy Admiraal of the Leiden University Libraries' Centre for Digital Scholarship explains where you can publish your dataset and tells us more about the Leiden University in-house DataverseNL repository.
Every year during the week of Valentine’s Day, we celebrate Love Data Week. This year the theme of the international celebration is 'Where’s the data?'. To us, data lovers, that sounds like a perfect invitation to ask ourselves the question: Where is our data? In this blog, we focus on published datasets and mainly describe our in-house data repository as a possible place where the data could be.
The Leiden University Data Repository
Research data can be published in different ways. What the best way is largely depends on the type of data, the repository that is suitable for your data, and on the objective of publishing the data. At Leiden University we offer an institutional data repository for researchers at the Faculty of Social and Behavioural Sciences, the Faculty of Governance and Global Affairs, and the Faculty of Humanities. The Leiden University Data Repository runs on the open source Dataverse software, of which the main branch is maintained by Harvard University. In the Netherlands, DANS (Data Archiving and Networking Services) provides the technical infrastructure, DataverseNL, and over 20 institutions are members of the Dutch consortium currently using it.
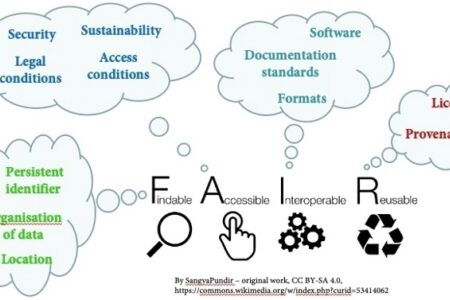
How the Leiden University Data Repository supports FAIR data
According to common guidelines and our University’s data management regulations, research data should be handled in line with the FAIR principles. As a researcher, you do not need to know all the technical details behind these principles, because the Leiden University Data Repository covers quite a few of them.
Findability
In the data repository, your dataset will be assigned a persistent identifier: a Digital Object Identifier (DOI). During the process of depositing the dataset, you will be asked to add metadata. Some of the fields are mandatory and others are optional. The richer the metadata that you provide, the better findable and discoverable your dataset is. For example, in a recently added dataset, the title, description, and keywords have all been filled in, so that someone searching for studies on federalism in Brazil can find the dataset through ‘Brazil’ being in the title and ‘federalism’ being a keyword. While the data files may not be accessible openly (some files can be restricted or closed), the metadata is shared as widely as possible. For example, the ODISSEI portal harvests metadata of Social Sciences datasets from various repositories, including the ones deposited in the Leiden University Data Repository, thus increasing their findability. Indeed, when searching for ‘federalism Brazil’ in the ODISSEI portal, the above-mentioned dataset is one of the 49 results.
Accessibility
According to the FAIR principles, the metadata and data must be retrievable via a standard technical protocol, and metadata must remain accessible even if the data themselves are no longer available. While the Leiden University Data Repository ensures this technical accessibility, as a user, you may have additional thoughts on who can have access to the data and why and when. The system allows for restrictions for accessing the data, but this relates more to data curation than to the FAIR principles (see below under access conditions).
Interoperability
The DataverseNL infrastructure is specifically intended as a data
repository. The data model behind the metadata follows standards, such as Dublin Core for the basic metadata. You also have the possibility to indicate relations between the dataset and other outputs, such as a journal article that is based on the data. This makes it easier to exchange information across systems. As a researcher, you can enhance the interoperability of your dataset even further by using vocabularies that are standard in your field (e.g. the Art and Architecture Thesaurus) when you are adding the metadata. This makes it easier for other researchers to know exactly what your dataset contains or what topics it covers. Furthermore, if you use file formats which are open and/or often used, this also makes it easier for others to read the dataset and combine it with their own data.
Reusability
One of the main reasons behind publishing research data is to make them available for others to reuse. This is only possibly if you document your data in such a way that others can understand what the data are about, ideally following standards that are common in your field or discipline. In addition, you need to set a usage licence that determines what others can do with the data once they have access to it. When depositing a dataset in the Leiden University Data Repository, you choose one of the licences from the Creative Commons licence options.
This dataset is published in the Leiden University Data Repository by researchers from the Centre for Science and Technology Studies. It contains the supplementary materials to their journal publication, which is cross-referenced in the metadata of the dataset. The dataset contains a collection of press releases from the EurekAlert! platform, as well as a README file that explains in more detail what the dataset entails. As it was not necessary to put any restrictions on the access conditions, all files are downloadable from the repository, to be reused under the applied licence CC-BY-NC 4.0. The files of this dataset have already been downloaded a total of 337 times.
Zhang, Jingwen; Jonathan Dudek; Alysson Mazoni; Enrique Orduna-Malea; Rodrigo Costas, 2025, "EurekAlert!: An open dataset for science communication research", https://doi.org/10.34894/EZO4JE, DataverseNL, V2.
In-house support and data curation
One of the main advantages of having an institutional data repository, is that it is managed within Leiden University. As a researcher, this means that you can get support while depositing your dataset, there is room for your influence on access conditions, and, if needed, the data will be deleted (deaccessioned) after a given amount of time.
Help with deposit
In each faculty using the Leiden University Data Repository a data steward is appointed as the data curator. The data curator has in-depth expertise in data management and is familiar with the data types typically handled in your institute or faculty. They can advise you on selecting and preparing the files for deposit, elaborating the documentation of your dataset, and filling out the metadata fields.
Access conditions
To Open or too Open; that’s a delicate question when publishing research data. In the light of Open Science, we advise to publish datasets as openly as possible, but as closed as necessary. There may be good reasons to restrict access to the data, for example for privacy or knowledge security reasons. In the Leiden University Data Repository, you can choose per file whether it can be openly accessible, needs to be under restricted access, or entirely closed. Together with the data curator, you can set the access conditions that apply when someone else would like access to the dataset. Putting an embargo on your dataset is also possible.
Data deaccessioning
Following the FAIR principles in the strictest sense, published data should remain available permanently. In practice, we see that there may be reasons to deaccession data at some point in time, for example when this is agreed upon with research participants in the signed informed consent form. When deleting data, in general, a workflow needs to be followed to comply with all regulations. The administrators of the Leiden University Data Repository have set up this workflow in collaboration with the central department Archive Management. As a researcher you indicate at the moment of deposit if some of your files will need to be deleted at some point, and when that time comes, you will be contacted again to sign off on the procedures.
During this year’s Love Data Week (9-13 February) several events are organised in the faculties that make use of the Leiden University Data Repository. Some of the events are open to the wider public. Please see the event pages linked below for more details:
9 February, 13:00-15:00
Humanities, all institutes
Open Office Hour – Hertha Mohr, room 2.29
10 February, 13.00-15.00
FSW (Social and Behavioural Sciences) / Psychology and Education and Child studies
Open Office Hour (every Tuesday) – Agora, room 4A22
12 February, 10.30-12.30
University-wide, UBL-CDS, Data Management Community
To keep or to discard: a workshop on data retention
12 February, 13.30-14.30
Law School, internal meeting
DataverseNL at Law: an introduction
12 February, 14.00-15.00
FGGA / all institutes
Open Office Hour – Wijnhaven, room 5.17
12 February, 15.00-16.30
FSW / Cultural Anthropology and Development Sociology, Political Science, and Centre for Science and Technology Studies
Towards an inventory of data, materials, and field devices in qualitative and ethnographic research at FSW
This blog was edited by Pascal Flohr. The blog text is reusable under a CC BY 4.0 licence. The banner image is by the University of Michigan Inter-university Consortium for Political and Social Research (ICPSR) and can be found on their International Love Data Week page.
The events list was edited on 9 February to reflect changes in the schedule.