



FAIR data's cutting edge
A three-point FAIRification framework was developed during the pandemic to pilot different ways of making COVID-19 data FAIR. Representatives from three cutting edge projects came to discuss with the Data Management Network the success of these, and the opportunities for new activities at Leiden.
On April 15, 2021, the Leiden University Data Management Network saw the launch of a new monthly meeting series with “Connect and Inspire: from F and A to I and R, how to implement research funders’ requirements”: a look at what’s going on at the cutting edge of FAIR (Findable, Accessible, Interoperable and Reusable) data.
Organised by the Leiden University Libraries' Centre for Digital Scholarship, this first “Connect and...” event brought together representatives from three GO-FAIR VODAN projects to present details of their success, and opportunities for Leiden to pilot and develop new activities. The presentations covered the delivery of Metadata4Machines workshops, the successful interrogation of data across international divides using FAIR Data Points, and Leiden’s involvement in developing tools that will help in the push towards more FAIR data.
The aim was to inspire members of the Leiden University Data Management Network to join, or start, new FAIR activities within the university.
Metadata4Machines (M4M)
The event was launched by Margreet Bloemers from ZonMw, the national Dutch funding organisation for health care research.
Leiden researchers will increasingly see demands from funders to make their data FAIR. Uploading datasets to a repository, perhaps with open access conditions, usually fulfils the findable and accessible requirements, but making them interoperable and reusable is a much greater challenge. Funders are increasingly seeing the importance of data sharing and data reuse to maximize their investment in research and to increase the speed at which new scientific discoveries are made.
Margreet detailed how ZonMw is pushing researchers towards FAIR data, not only as a funder, but as a facilitator and a consortium partner: enabling communities towards FAIR data practices, and helping to push forward FAIR data solutions.
She gave a fascinating insight into the COVID-19 funding programme, for which ZonMw has been delivering Metadata4Machines (M4M) training to researcher/data steward partnerships. M4M workshops bring together researchers and data stewards to discuss metadata possibilities at the start of a research project so that data can be collected according to pre-defined templates that make it easier to expose the collected data in a FAIR way.
The series of intensive training events has resulted in several machine-actionable metadata templates that they are now preparing to share via the Health-RI portal (a FAIR Data Point) that has been created for the purpose of sharing COVID-19 data and metadata.
VODAN – Virus Outbreak Data Network
Kristina Hettne and Joanne Yeomans from Leiden University Libraries’ Centre for Digital Scholarship explained how the Centre for Digital Scholarship has been heavily involved in the Virus Outbreak Data Network (VODAN) initiative, as a leader of the Data Stewardship cluster and as a member of the FAIR Core Specs cluster, and the development of the Three-Point FAIRification Framework during the last year.
The VODAN Data Stewardship cluster has been central in raising questions and prompting debate within the GOFAIR movement about how FAIR data can be achieved. Originally charged with coordinating data stewards, the cluster of volunteers first went through a process of learning and understanding more about the technicalities of creating FAIR data, and as a result, are now involved in producing explanatory and training materials to convince, and develop understanding, among decision-makers and RDM support staff at research institutions around the world.
This process of learning whilst doing, is where opportunities lie for getting involved, leading from the front, and hence learning first-hand what it means to create FAIR data.
In the FAIR Core Specs cluster the actual components of the Three-Point FAIRification Framework (Metadata4Machine workshops, FAIR Implementation Profiles and FAIR Data Points) were further developed and defined together with stakeholders.
Areas that Leiden University might work on during the next year include:
- testing out M4M workshops with different groups to see how these can be scaled up across the university,
- looking into FAIR Implementation Profiles and how these link with data management plans,
- setting up a FAIR Data Point and testing this out with real data,
- producing training and explanatory materials for others.
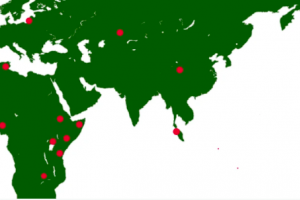
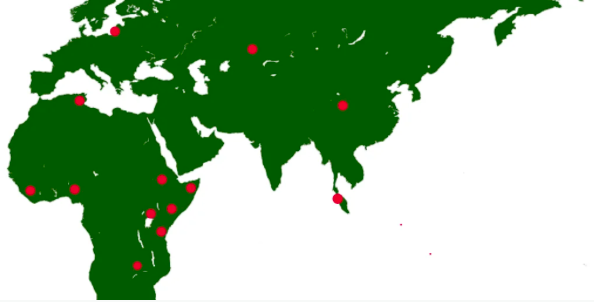
FAIR Data Points
Mirjam van Reisen, Professor of FAIR Data Science at the Leiden University Medical Centre (LUMC), presented details of a ground-breaking pilot that has seen FAIR data deployed in the LUMC and in health facilities on other continents, including Africa. The machine-readable data, which includes both clinical patient data and research data, is owned by the clinics and can be visited by algorithms. The research is part of the COVID-related VODAN Africa-Asia project and was recognized in UNESCO’s Engineering for Sustainable Development report published in March this year.
Project participants went through a series of webinars to learn more about FAIR data, then a series of M4M workshops, and then through a guided installation of FAIR Data Points. The FAIR Data Points were successfully interrogated in September 2020. A second webinar series looked at the country contexts, the challenges encountered, and the opportunities for combating socioeconomic challenges caused by COVID-19. The VODAN Africa-Asia project website offers a wealth of materials and recordings from these events that might be useful to others.
Mirjam described the wide range of backgrounds that they had called upon during the project to build the FAIR Data Points, but also to develop the agreements and policies in order to populate the Data Points with COVID data collected electronically using the WHO eCRF (Case Report Forms): ethnographers, graduate students in computing and IT, biologists, virologists, medical doctors, artists (for portal design and promotion), medical records managers, and statisticians.
Developing a FAIR Data Point is clearly not only a technical question, but also a complex interweaving of policies, practices, and procedures.

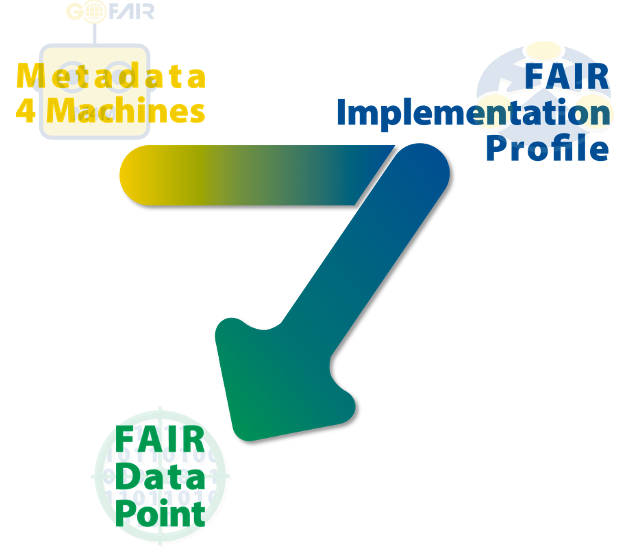
What's next for Leiden?
The aim of the meeting was to stimulate discussion and inspire Network members to think about what we can do next at Leiden University to develop our understanding of what’s possible, and to improve the FAIRness of researchers’ datasets.
Some Network members stayed for an extra half an hour at the end of the meeting to discuss how to move forwards with these initiatives at Leiden University and there’s sufficient interest to organise a follow-up meeting to make plans for the next steps. There is also interest to learn more about FAIR Implementation Profiles – something that was mentioned, but not presented in detail during this meeting.
Both Margreet Bloemers and Mirjam van Reisen are keen to stay involved with us to collaborate and build upon these previous successes, and we will therefore discuss with them how we can work together.
If you’re interested in learning more about FAIR data by being involved in one of the developments, or you have a suggestion for a topic for a future Connect and... event, get in touch with Kristina or Joanne.


